Attrs, Dataclasses and Pydantic
Posted on
I’ve been using attrs for a long time now and I am really liking it. It is very flexible, has a nice API, is well documented and maintained, and has no runtime requirements.
The main idea behind attrs was to make writing classes with lots of data attributes (“data classes”) easier. Instead of this:
class Data:
def __init__(self, spam, eggs):
self.spam = spam
self.eggs = eggs
It lets you write this:
@attr.s
class Data:
spam = attr.ib()
eggs = attr.ib()
Attrs also adds a nice string representation, comparison methods, optional validation and lots of other stuff to your classes, if you want to. You can also opt out of everything; attrs is very flexible.
Attrs became so popular, that since Python 3.7 we also have the dataclasses module in the standard library. It is predominantly inspired by attrs (the attrs team was involved in the design of data classes) but has a smaller feature set and will evolve a lot slower. But you can use it out-of-the box without adding a new requirement to your package.
Pydantic’s development roughly started during Python 3.7 development, too. Its main focus is on data validation, settings management and JSON (de)serialisation, therefore it is located at a higher level ob abstraction. Out of the box, it will recursively validate and convert all data that you pour into your model:
>>> from datetime import datetime
>>> from pydantic import BaseModel
>>>
>>> class Child(BaseModel):
... x: int
... y: int
... d: datetime
...
>>> class Parent(BaseModel):
... name: str
... child: Child
...
>>> data = {
... 'name': 'spam',
... 'child': {
... 'x': 23,
... 'y': '42', # sic!
... 'd': '2020-05-04T13:37:00',
... },
... }
>>> Parent(**data)
Parent(name='spam', child=Child(x=23, y=42, d=datetime.datetime(2020, 5, 4, 13, 37)))
I only learned about pydantic when I started to work with FastAPI. FastAPI is a fast, asynchronous web framework specifically designed for building REST APIs. It uses pydantic for schema definition and data validation.
Since then, I asked myself: Why not attrs? What’s the benefit of pydantic over the widely used and mature attrs? Can or should it replace attrs?
As I begin to write this article, I still don’t know the answer to these questions. So lets explore attrs, data classes and pydantic!
Simple class definition
Originally, attrs classes were created by using the @attr.s()
(or @attr.attrs() class decorator. Fields had to be created via
the attr.ib() (or @attr.attrib()) factory function. By
now, you can also create them nearly like data classes.
The recommended way for creating pydantic models is to subclass
pydantic.BaseModel. This means that in contrast to data
classes, all models inherit some “public” methods (e.g., for JSON
serialization) which you need to be aware of. However, pydantic allows
you to create stdlib data classes extended with validation, too.
Here are some very simple examples for data classes / models:
>>> import attr
>>> import dataclasses
>>> import pydantic
...
...
>>> # Simple data classes are supported by all libraries:
>>> @attr.dataclass
... # @dataclasses.dataclass
... # @pydantic.dataclasses.dataclass
... class Data:
... name: str
... value: float
...
>>> Data('Spam', 3.14)
Data(name='Spam', value=3.14)
...
...
>>> @attr.s
... class Data:
... name = attr.ib()
... value = attr.ib()
...
>>> Data('Spam', 3.14)
Data(name='Spam', value=3.14)
...
...
>>> class Data(pydantic.BaseModel):
... name: str
... value: float
...
>>> Data(name='Spam', value=3.14)
Data(name='Spam', value=3.14)
Pydantic models enforce keyword only arguments when creating new instances. This is a bit tedious for classes with only a few attributes but with larger models, you’re likely going to use keyword arguments anyways. The benefit of kw-only arguments is, that it doesn’t matter if you list attributes with a default before ones without a default.
Data classes support positional as well as keyword arguments. Passing values by position is very convenient for smaller classes but that also means that you must define all fields without a default value first and the ones with a default value afterwards. This may prevent you from grouping similar attributes, when only some of them have a default value.
Attrs supports both ways. The default is to allow positional and
keyword arguments like data classes. You can enable kw-only arguments
by passing kw_only=True to the class decorator.
Another major difference is that Pydantic always validates and converts all attribute values, but more on that later.
Class and attribute customistaion
All three libraries let you customize the created fields as well as the class itself.
In data classes and attrs, you can customize your class by passing additional arguments to the class decorator. Pydantic models can define a nested Config class for the same purpose.
Attributes can be customized via special factory functions. Instead of
specifying an attribute like this: name: type [= default], you
you do: name: type = field_factory(). This function is named
[attr.]ib()/attrib() in attrs, field() with data
classes and Field() in pydantic.
Using these functions, you can specify default values, validators, meta data and other attributes. The following tables let you compare the customisation features that each library provides:
| attrs | data classes | pydantic | |
|---|---|---|---|
| Explicit no default | NOTHING 1 |
MISSING 1 |
... 1 |
| Default factory | yes | yes | yes |
| Validators | yes 2 | no | no 2,3 |
| Constraints | no | no | const, regex, length, number range, … |
| Converters | yes 2 | no | no 2,3 |
| Exclude field from | repr, eq, order, hash, init | repr, compare, hash, init | ø |
| Add arbitrary metadata | yes | yes | yes |
| Additional docs | no | no | title, description |
| attrs | data classes | pydantic | |
|---|---|---|---|
| Auto create methods for | str, repr, equality, ordering, hash, init | repr, equality, ordering, hash, init | str, repr, equality, init |
| Keyword args only | optional | no | yes |
| Faux immutability / Freezing | yes | yes | yes |
| Slots | yes | no | no |
| Safe to subclass exceptions | yes | no | no |
| Dynamic creation | yes | yes | yes |
| Instantiate from dict | yes | yes | yes, recursively |
| Instantiate from objects | no | no | optional, recursively |
| Instantiate from JSON | no | no | yes, recursively |
| Instantiate from env. vars. | no | no | yes, recursively |
Generated methods
All libraries create useful “dunder” methods (like __init__() or
__str__()). Attrs can generate the most methods, followed by
data classes and Pydantic. Attrs and data classes also allow you to
selectively disable the generation of certain methods.
Attrs is the only library that generates __slots__ and is also the only one that has explicit support for subclassing exceptions.
Default values
Without a field factory, default values for fields are simply assigned
to the field name, e.g., value: int = 42. When you use a field
factory, you can/need to pass a default value as argument to that
function. In pydantic, the default value is always passed as first
positional argument. In order to express “this attribute has no
default”, you use the elipsis literal (...). Data classes use
the optional keyword argument default instead. Attrs lets you
choose - you can pass a default value by position or as keyword argument.
Another difference is that pydantic allows you to use mutable objects like lists or dicts as default values. Attrs and data classes prohibit this for good reason. To prevent bugs with mutable defaults, pydantic deep-copies the default value for each new instance.
You you can specify factories for default values with all libraries.
Freezing and functional programming
You can create pseudo immutable classes with all libraries. Immutable/frozen instances prevent you from changing attribute values. This helps when you aim to program in a more functional style. However, if attributes themselves are mutable (like lists or dicts), you can still change these!
In attrs and data classes, you pass frozen=True to the class
decorator. In pydantic, you set allow_mutation = False in the
nested Config class.
Attrs and data classes only generate dunder protocol methods, so your classes are “clean”. Having struct-like, frozen instances make it relatively easy to write purely functional code, that can be more robust and easier to test than code with a lot of side effects.
Pydantic models, on the other hand, use inheritance and always have some methods, e.g., for converting an instance from or to JSON. This facilitates a more object-orient programming style, which can be a bit more convenient in some situations.
Instantiation, validation and conversion
The main differentiating features of pydantic are its abilities to create, validate and serialize classes.
You can instantiate pydantic models not only from dicts/keyword arguments but also from other data classes (ORM mode), from environment variables, and raw JSON. Pydantic will then not only validate/convert basic data types but also more advanced types like datetimes. On top of that, it will recursively create nested model instances, as shown in the example above.
Model instances can directly be exported to dicts and JSON via the
.dict()/.json() methods.
To achieve something similar in attrs or data classes, you need to install an extension package like, for example, cattrs. And even then, Pydantic has a far better user experience.
Apart from that, all libraries allow you to define custom validator and converter functions. You can either pass these functions to the field factories or define decorated methods in your class.
Metadata and schema generation
Pydantic can not only serialize model instances but also the schema of the model classes themselves. This is, for example, used by FastAPI to generate the OpenAPI spec for an API.
To aid the documentation of the generated schemas, every field can have a title and a description attribute. These are not used for docstrings, though.
Documentation
In a way, the documentation of all three projects mirrors their feature sets.
It is of high quality in all cases, but technically and in terms of content very different.
The data classes documentation is part of Python’s stdlib documentation and the briefest of all candidates, but it covers everything you need to know. It contains a direct link to the source code that also has many helpful comments.
The attrs docs contain example based guides, in-depth discussions of certain features and design decisions as well as an exhaustive API reference. It uses Sphinx and, for the API reference, the autodoc extension. It provides an objects inventory which allows you to cross-reference attrs classes and functions from your own documentation via intersphinx.
The pydantic documentation is also very well written and contains many good examples that explain almost all functionality in great detail. However, it follows the unfortunate trend of using MkDocs as a documentation system. I assume that this is easier to set-up then Sphinx and allows you to use Markdown instead of ReStructuredText, but it is also lacking lots of important features and I also don’t like its UX. It has two navigation menus – one on the left for whole document’s TOC and one on the right for the current page. More serious, however, is the absence of an API reference. There is also no cross referencing (e.g., links from class and function names to their section in the API reference) and thus no objects inventory that can be used for inter-project cross referencing via Sphinx’ intersphinx extension. Even pydantic’s source code barely includes any docstrings or other comments. This can be a hindrance when you want to solve more advanced problems.
Performance
For most use cases, the performance of a data classes library can be neglected. Performance differences only become noticeable when you create thousands or even millions of instances in a short amount of time.
However, the pydantic docs contain some benchmarks that suggest that pydantic is slightly ahead of attrs + cattrs in mean validation time. I was curious why pydantic, despite its larger feature set, was so fast, so I made my own benchmarks.
I briefly evaluate the attrs extension packages. The only one that offers reasonably convenient means for input validation and (de)serialization as well as good performance is cattrs.
I created benchmarks for three different use cases:
- Simple classes and no need for extensive validation
- Deserialization and validation of (more) complex (nested) classes
- Serialization of complex (nested) classes
I calculated the time and memory consumption for handling 1 million instances of different variants of attrs and data classes as well as pydantic models.
Unsurprisingly, attrs and data classes are much faster than pydantic when no validation is needed. They also use a lot less memory.
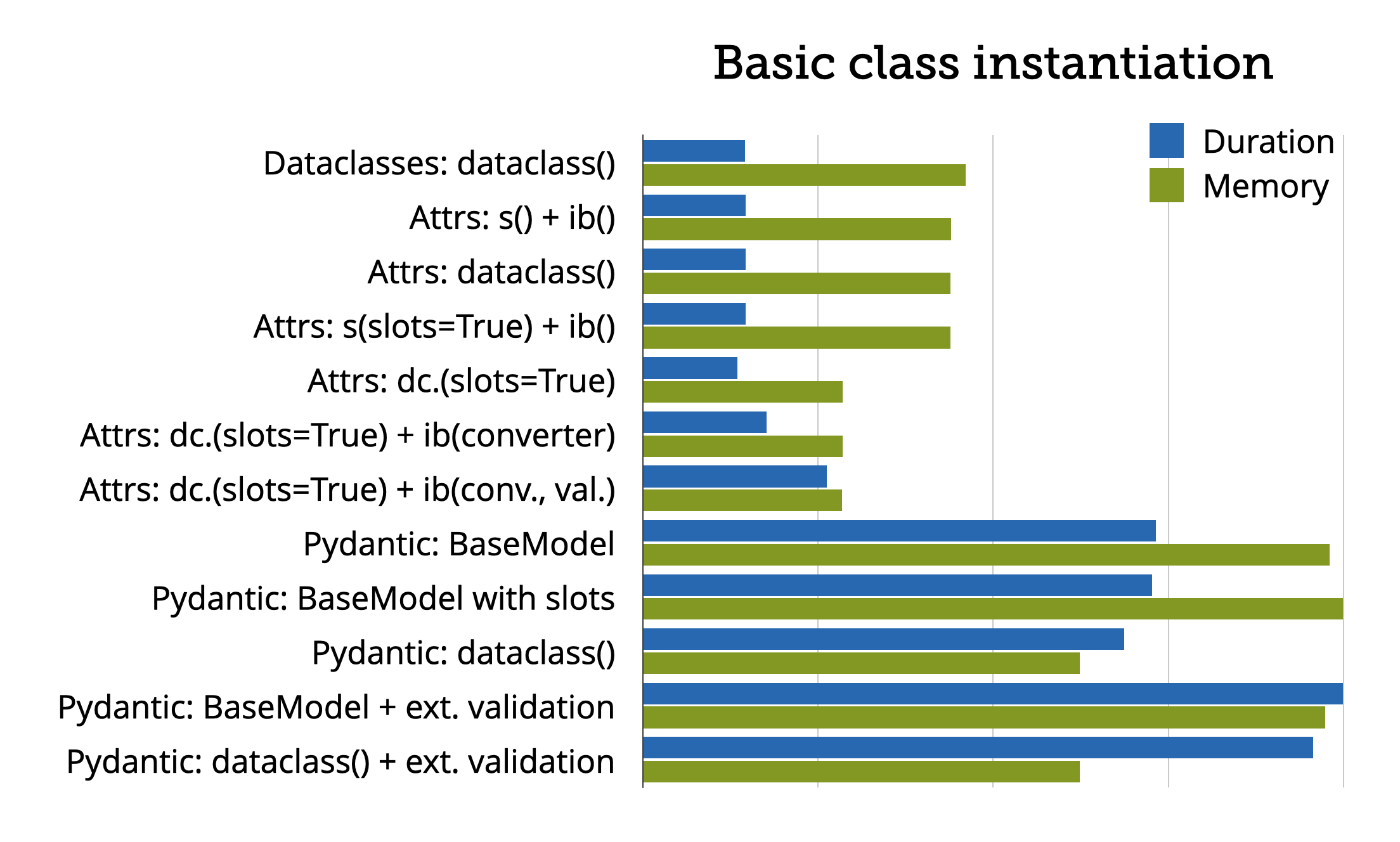
I was expecting that the results would be much closer when it comes to validation/conversion and serialization, but even there, pydantic was a lot slower than attrs + cattrs.

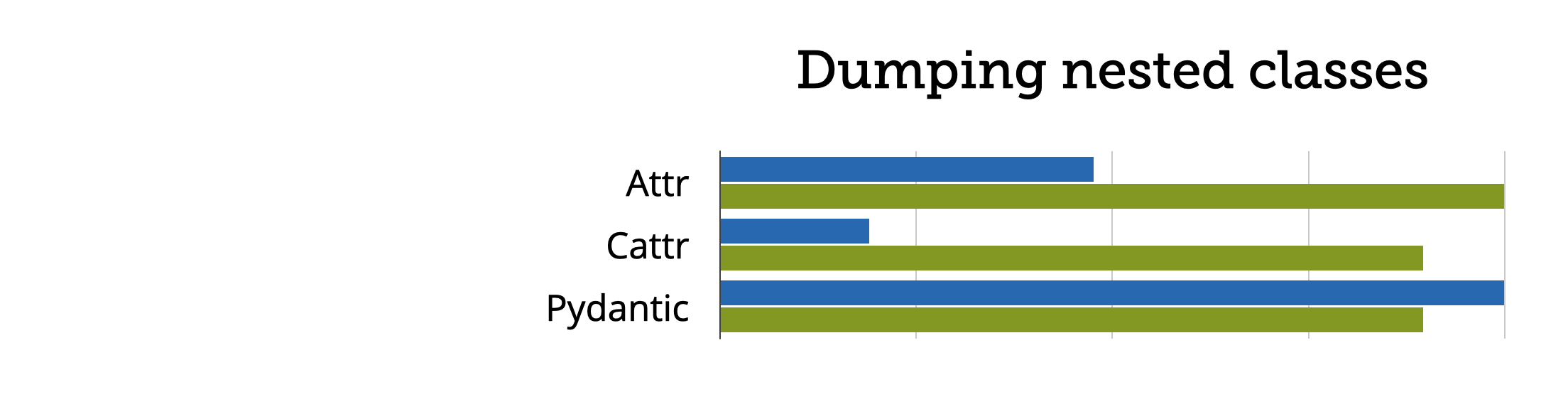
I wondered why my benchmarks were so clearly in favor of attrs when the
pydantic docs state that it is 1.4x faster than attrs + cattrs. I tried
running the pydantic benchmarks myself and indeed I could reproduce
these results. Wondering, why the results differed so much, I took
a closer look at the benchmark’s source code. It turned out that the
attrs + cattrs example used python-dateutil for parsing datetimes
while pydantic uses its own implementation. I replaced
datetuil.parser.parse() with the stdlib
datetuil.fromisoformat() and the attrs + cattrs example suddenly
became 6–7 times faster. (Note: fromisoformat() is not
a general purpose parser!)
In defense of pydantic: The attrs + cattrs (de)serializers were specifically designed and implemented for this benchmark while Pydantic ships everything out-of-the box. Pydantic’s UX for these use cases is also more pleasant than that of attrs + cattrs.
You can find the source of all benchmark in the accompanying repository.
Summary
Attrs, data classes and pydantic seem very similar on a first glance, but they are very different when you take a closer look.
All three projects are of high quality, well documented and generally pleasant to use. Furthermore, they are different enough that each of them has its niche where it really shines.
The stdlib’s data classes module provides all you need for simple use cases and it does not add a new requirement to your project. Since it does not do any data validation, it is also quite fast.
When you need more features (more control over the generated class or
data validation and conversion), you should use attrs. It is as fast as
data classes are but its memory footprint is even smaller when you
enable __slots__.
If you need extended input validation and data conversion, Pydantic is the tool of choice. The price of its many features and nice UX is a comparatively bad performance, though.
If you want to cut back on UX instead, the combination of attrs and cattrs might also be an alternative.
You can take a look at the benchmarks to get a feel for how the libraries can be used for different use cases and how they differ form each other.
I myself will stay with attrs as long as it can provide what I need. Otherwise I’ll use Pydantic.
Epilogue
I wish there was a library like mattrs (magic attrs) that combined Pydantic’s (de)serialization UX with attrs’ niceness and performance:
>>> from datetime import datetime
>>> from mattrs import dataclass, field, asjson
>>>
>>> @dataclass()
... class Child:
... x: int = field(ge=0, le=100)
... y: int = field(ge=0, le=100)
... d: datetime
...
>>> @dataclass()
... class Parent:
... name: str = field(re=r'^[a-z0-9-]+$')
... child: Child
...
>>> data = {'name': 'spam', 'child': {'x': 23, 'y': '42', 'd': '2020-05-04T13:37:00'}}
>>> Parent(**data)
Parent(name='spam', child=Child(x=23, y=42, d=datetime.datetime(2020, 5, 4, 13, 37)))
>>> asjson(_)
{"name": "spam", "child": {"x": 23, "y": 42, "d": "2020-05-04T13:37:00"}}
Maybe it’s time for another side project? 🙊