Packaging Python inside your organization with GitLab and Conda
Posted on
Python Packaging has recently been discussed a lot, but the articles usually only focus on publishing (open source) code to PyPI.
But what do you do when your organization uses Python for in-house development and you can’t (or don’t want to) make everything Open Source? Where do you store and manage your code? How do you distribute your packages?
In this article, I describe how we solve this problem with GitLab, Conda and a few other tools.
You can find all code and examples referenced in this article under
gitlab.com/ownconda. These tools and examples are using the own prefix
in order to make a clear distinction between our own and third-party code.
I will not necessarily update and fix the code, but it is released under the
Blue Oak license so you can copy and use it. Any feedback is welcome, nonetheless.
Software selection
In this section I’ll briefly explain the reasons why we are using GitLab and Conda.
Code and issue management
Though you could use private repositories from one of the well-known cloud services, you should probably use a self-hosted service to retain full control over your code. In some countries it may even be forbidden to use a US cloud service for your organization’s data.
There are plenty of competitors in this field: GitLab, Gitea, Gogs, Gitbucket or Kallithea—just to name a few.
Our most important requirements are:
- Repository management
- Pull/Merge requests
- Issue management
- CI/CD pipelines
The only tool that (currently) meets these requirements is GitLab. It has a lot more features that are very useful for an organization wide use, e.g., LDAP and Kerberos support, issue labels and boards, Mattermost integration or Git LFS support. And—more importantly—it also has a really nice UX and is one of the few pieces of software that I actually enjoy using.
GitLab has a free core and some paid versions that add more features and support.
The package manager: Pip or Conda?
Pip is the official package installer for Python. It supports Python
source distributions and (binary) Wheel packages. Pip only installs files in
the current environment’s site-packages directory and can optionally
create entry points in its bin directory. You can use Virtualenv to
isolate different projects from another, and Devpi to host your own package
index. Devpi can both, mirror/cache PyPI and store your own packages. The Python packaging ecosystem is overlooked by the Python
Packaging Authority working group (PyPA).
Conda stems from the scientific community and is being developed by Anaconda.
In contrast to Pip, Conda is a full-fledged package manager similar to
apt or dnf. Like virtualenv, Conda can create isolated
virtual environments. Conda is not directly compatible with Python’s
setup.py or pyproject.toml files. Instead, you have to create
a Conda recipe for every package and build it with conda-build.
This is a bit more involved because you have to convert every package that you
find on PyPI, but it also lets you patch and extend every package. With very
little effort you can create a self-extracting Python distribution with
a selection of custom packages (similar to the Miniconda distribution).
Conda-forge is a (relatively) new project that has a huge library of Conda recipes and packages. However, if you want full control over your own packages you may want to host and build everything on your own.
What to use?
- Both, Conda and pip, allow you to host your own packages as well as 3rd party packages inside your organization.
- Both, Conda and pip, provide isolated virtual environments.
- Conda can package anything (Python, C-libraries, Rust apps, …) while Pip is exclusively for Python packages.
- With Conda, you need to package and build everything on your own. Even packages from PyPI need to be re-packaged. On the other side, this makes it easier to patch and extend the package’s source.
- Newer Conda versions allow you to build everything on your own, even GCC and libc. This is, however, not required and you can rely on some low-level system libraries like the manylinux standard for Wheels does. (You just have to decide which ones, but more on that later.)
- Due to its larger scope, Conda is slower and more complex than Pip. In the past, even patch releases introduced backwards incompatible changes and bugs that broke our stack. However, the devs are very friendly and usually fix critical bugs quite fast. And maybe we would have had similar problems, too, if we used a Pip based stack.
Because we need to package more than just Python, we chose to use Conda. This dates back to at least to Conda v2.1 which was released in 2013. At that time, projects like conda-forge weren’t even in sight.
Supplementary tools
To aid our work with GitLab and Conda, we developed some supplementary tools. I have released a slightly modified version of them, called ownconda tools, alongside with this article.
The ownconda tools are a click based collection of commands that reside under the entry point ownconda.
Initially, they were only meant to help with the management of recipes for external packages, and with running the build/test/upload steps in our GitLab pipeline. But they have become a lot more powerful by now and even include a GitLab Runner that lets you run your projects’ pipelines locally (including artifacts handling, which the official gitlab-runner cannot do locally).
$ ownconda --help
Usage: ownconda [OPTIONS] COMMAND [ARGS]...
Support tools for local development, CI/CD and Conda packaging.
Options:
--help Show this message and exit.
Commands:
build Build all recipes in RECIPE_ROOT in the correct...
check-for-updates Update check for external packages in RECIPE_ROOT.
ci Run a GitLab CI pipeline locally.
completion Print Bash or ZSH completion activation script.
dep-graph Create a dependency graph from a number of Conda...
develop Install PATHS in develop/editable mode.
gitlab Run a task on a number of GitLab projects.
lint Run pylint for PATHS.
make-docs Run sphinx-build and upload generated html...
prune-index Delete old packages from the local Conda index at...
pylintrc Print the built-in pylintrc to stdout.
pypi-recipe Create or update recipes for PyPI packages.
sec-check Run some security checks for PATHS.
show-updated-recipes Show updated recipes in RECIPE_ROOT.
test Run tests in PATHS.
update-recipes Update Conda recipes in RECIPE_ROOT.
upload Upload Conda packages in PKG_DIR.
validate-recipes Check if recipes in RECIPE_ROOT are valid.
I will talk about the various subcommands in more detail in later sections.
How it should work
The subject of packaging consists of several components: The platforms on which your code needs to build and run, the package manager and repository, management of external and internal packages, a custom Python distribution, and means to keep an overview over all packages and their dependencies. I will go into detail about each aspect in the following sections.
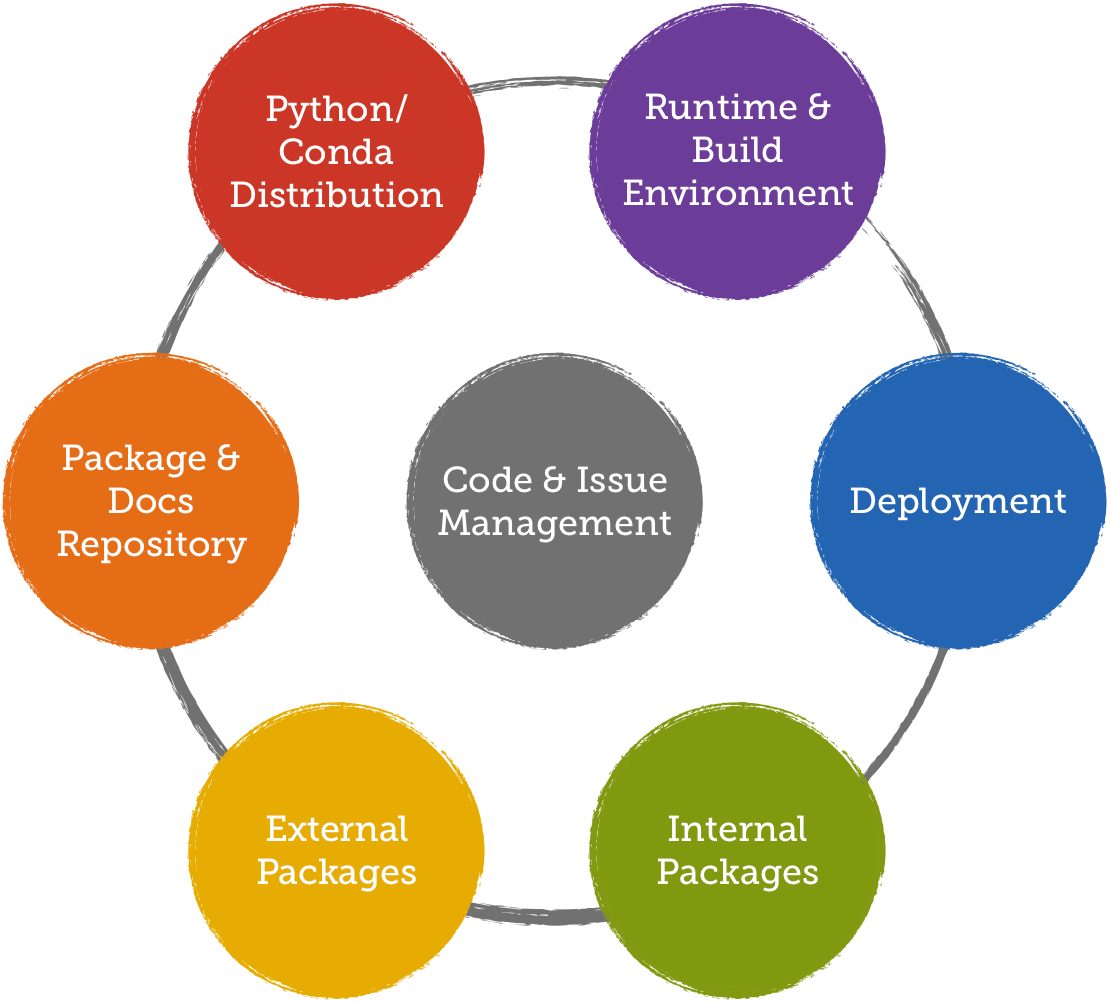
Runtime and build environment
Our packages need to run on Fedora desktop systems and on Centos 7. Packages built on Centos also run on Fedora, so we only have a single build environment: Centos 7.
We use different Docker images for our build pipeline and some deployments. The most important ones are centos7-ownconda-runtime and centos7-ownconda-develop. The former only contains a minimal setup to install and run Conda packages while the latter includes all build dependencies, conda-build and the ownconda tools.
If your OS landscape is more heterogeneous, you may need to add more build environments which makes things a bit more complicated—especially if you need to support macOS or even Windows.
To build Docker images in our GitLab pipelines, we use docker-in-docker.
That means that the GitLab runners start docker containers that can access
/var/run/dockers.sock to run docker build.
GitLab provides a Docker registry that allows any project to host its own images. However, if a project is private, other project’s pipelines can not access these images. For this reason, we have decided to serve Docker images from a separate host.
3rd party packages
We re-package all external dependencies as Conda packages and host them in our own Conda repository.
This has several benefits:
- We can prohibit installing Software from other sources than our internal Conda repository.
- If users want to depend on new libraries, we can propose alternatives that we might already have on our index. This keeps our tree of dependencies a bit smaller.
- We cannot accidentally depend on packages with “bad” licenses.
- We can add patches to fix bugs or extend the functionality of a package (e.g., we added our internal root certificate to Certifi).
- We can reduce network traffic to external servers and are less dependent on their availability.
Recipe organization
We can either put the recipe for every package into its own repository (which is what conda-forge does) or use a single repository for all recipes (which is what we are doing).
The multi-repository approach makes it easier to only build packages that have changed. It also makes it easier to manage access levels if you have a lot of contributors that each only manage a few packages.
The single-repository approach has less overhead if you only have a few maintainers that take care of all the recipes. To identify updated packages that need re-building, we can use ownconda’s show-updated-recipes command.
Linking against system packages
With Conda, we can (and must) decide whether we want to link against system packages (e.g., installed with yum or use other Conda packages to satisfy a package’s dependencies.
One extreme would be to only build Python packages on our own and completely depend on system packages for all C libraries. The other extreme would be to build everything on our own, even glibc and gcc.
The former has a lot less overhead but becomes the more fragile the more heterogeneous your runtime environments become. The latter is a lot more complicated and involved but gives you more control and reliability.
We decided to take the middle ground between these two extremes: We build many libraries on our own but rely on the system’s gcc, glibc, and X11 libraries. This is quite similar to what the manylinux standard for Python Wheels does.
Recipes must list the system libraries that they link against. The rules for valid system libraries are encoded in ownconda validate-recipes and enforced by conda-build’s –error-overlinking option.
Recipe management
Recipes for Python packages can easily be created with ownconda pypi-recipe. This is similar to conda skeleton pypi but tailored to our needs. Recipes for other packages have to be created manually.
We also implemented an update check for our recipes. Every recipe contains
a script called update_check.py which uses one of the update checkers
provided by the ownconda tools.
These checkers can query PyPI, GitHub release lists and (FTP) directory listings, or crawl an entire website. The command ownconda check-for-updates runs the update scripts and compares the version numbers they find against the recipes’ current versions. It can also print URLs to the packages’ changelogs:
$ own check-for-updates --verbose .
[████████████████████████████████████] 100%
Package: latest version (current version)
freetype 2.10.0 (2.9.1):
https://www.freetype.org/index.html#news
python-attrs 19.1.0 (18.2.0):
http://www.attrs.org/en/stable/changelog.html
python-certifi 2019.3.9 (2018.11.29):
https://github.com/certifi/python-certifi/commits/master
...
qt5 5.12.2 (5.12.1):
https://wiki.qt.io/Qt_5.12.2_Change_Files
readline 8.0.0 (7.0.5):
https://tiswww.case.edu/php/chet/readline/CHANGES
We can then update all recipes with ownconda update-recipes:
$ ownconda update-recipes python-attrs ...
python-attrs
cd /data/ssd/home/stefan/Projects/ownconda/external-recipes && /home/stefan/ownconda/bin/python -m own_conda_tools pypi-recipe attrs -u
diff --git a/python-attrs/meta.yaml b/python-attrs/meta.yaml
index 7d167a8..9b3ea20 100644
--- a/python-attrs/meta.yaml
+++ b/python-attrs/meta.yaml
@@ -1,10 +1,10 @@
package:
name: attrs
- version: 18.2.0
+ version: 19.1.0
source:
- url: https://files.pythonhosted.org/packages/0f/9e/26b1d194aab960063b266170e53c39f73ea0d0d3f5ce23313e0ec8ee9bdf/attrs-18.2.0.tar.gz
- sha256: 10cbf6e27dbce8c30807caf056c8eb50917e0eaafe86347671b57254006c3e69
+ url: https://files.pythonhosted.org/packages/cc/d9/931a24cc5394f19383fbbe3e1147a0291276afa43a0dc3ed0d6cd9fda813/attrs-19.1.0.tar.gz
+ sha256: f0b870f674851ecbfbbbd364d6b5cbdff9dcedbc7f3f5e18a6891057f21fe399
build:
- number: 1
+ number: 0
...
The update process
Our Conda repository has various channels for packages of different maturity, e.g. experimental, testing, staging, and stable.
Updates are first built locally and uploaded to the testing channel for some manual testing.
If everything goes well, the updates are committed into the develop
branch, pushed to GitLab and uploaded to the staging channel. We
also send a changelog around to notify everyone about important
updates and when they will be uploaded into the stable channel.
After a few days in testing, the updates are merged into the master
branch and upload to the stable channel for production use.
This is a relatively save procedure which (usually) catches any problems before they go into production.
Example recipes
You can find the recipes for all packages required to run the ownconda tools here. As a bonus, I also added the recipes for NumPy and PyQt5.
Internal projects
Internal packages are structured in a similar way to most projects that you see
on PyPI. We put the source code into src, the pytest tests into
tests and the Sphinx docs into docs. We do not use namespace
packages. They can lead to various nasty bugs. Instead, we just prefix all
packages with own_ to avoid name clashes with other packages and to easily
tell internal and external packages apart.

The biggest difference to “normal” Python projects is the additional Conda
recipe in each project. It contains all meta data and the requirements. The
setup.py contains only the minimum amount of information to get the
package installed via pip:
- Conda-build runs it to build the Conda package.
- ownconda develop runs it to install the package in editable mode.
ownconda develop also creates/updates a Conda environment for the current project and installs all requirements that it collects from the project’s recipe.
Projects also contain a .gitlab-ci.yml which defines the GitLab CI/CD
pipeline. Most projects have at least a build, a test and an upload
stage. The test stage is split into parallel steps for various test tools
(e.g., pytest, pylint and bandit). Projects can optionally build
documentation and upload it to our docs server. The ownconda tools provide
helpers for all of these steps:
- ownconda build builds the package.
- ownconda test runs pytest.
- ownconda lint runs pylint.
- ownconda sec-check runs bandit.
- ownconda upload uploads the package to the package index.
- ownconda make-docs builds and uploads the documentation.
We also use our own Git flow:
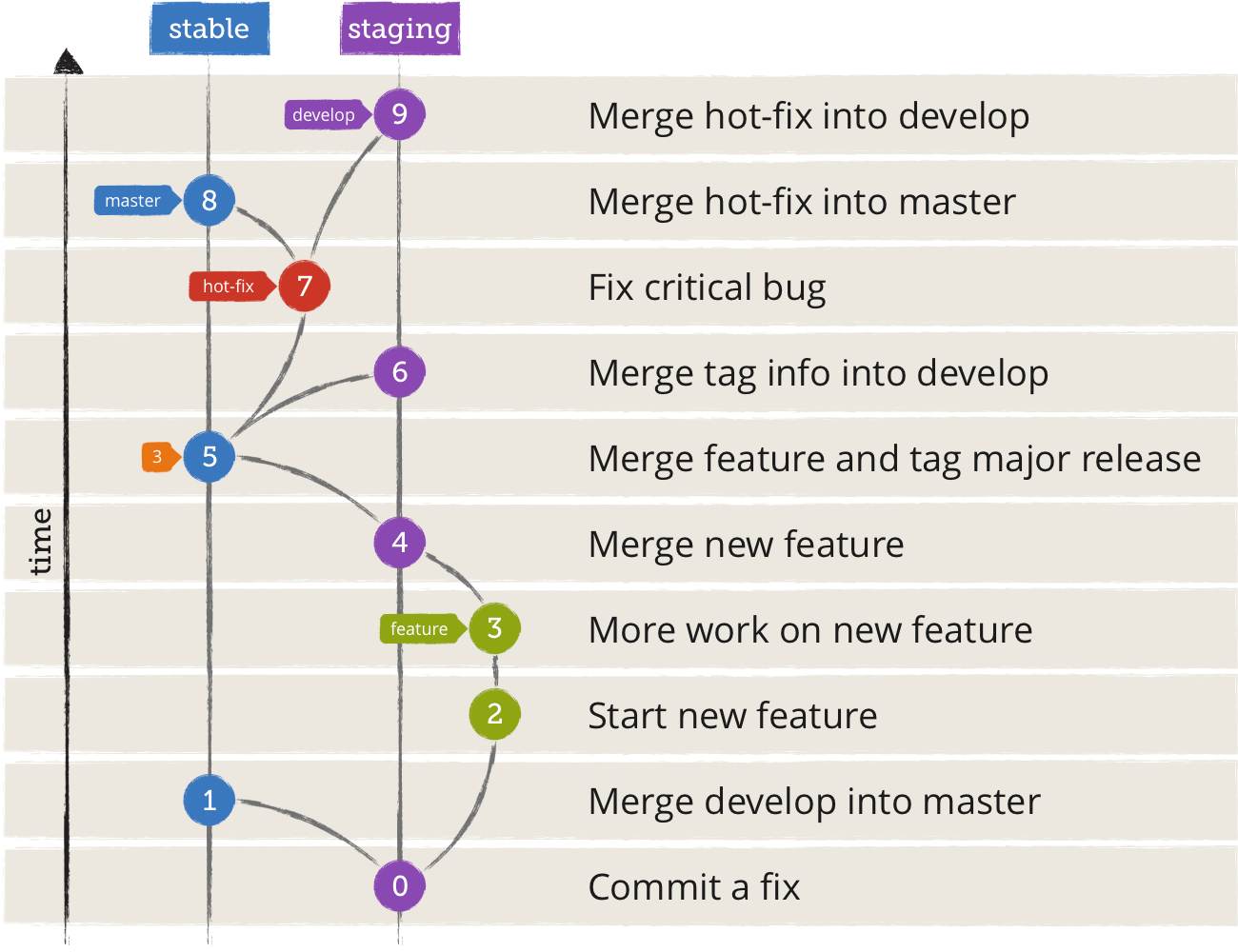
Development happens in a
developbranch. Builds from this branch are uploaded into a staging Conda channel.Larger features can optionally branch of a feature branch. Their builds are not uploaded into a public Conda channel.
Stable
developstates get merged into the master branch. Builds are uploaded into our stable Conda channel.Since we continuously deploy packages, we don’t put a lot of effort into versioning. The package version consists of a major release which rarely changes and the number of commits since the last tagged major release. The GitLab pipeline ID is used as a build number:
- Version:
$GIT_DESCRIBE_TAG.$GIT_DESCRIBE_NUMBER - Build:
py37_$CI_PIPELINE_ID
The required values are automatically exported by Conda and GitLab as environment variables.
- Version:
Package and documentation hosting
Hosting a Conda repository is very easy. In fact, you can just run python -m
http.server in your local Conda base directory if you previously built any
packages. You can then use it like this: conda search
--override-channels --channel=http://localhost:8000/conda-bld PKG.
A Conda repository consists of one or more channels. Each channel is
a directory that contains a noarch directory and additional platform
directories (like linux-64). You put your packages into these
directories and run conda index channel/platform to create an index
for each platform (you can omit the platform with newer versions of
conda-build). The noarch directory must always exist, even
if you put all your packages into the linux-64 directory.
The base URL for our Conda channels is
https://forge.services.own/conda/channel. You can put a static
index.html into each channel’s directory that parses the repo data and
displays it nicely:
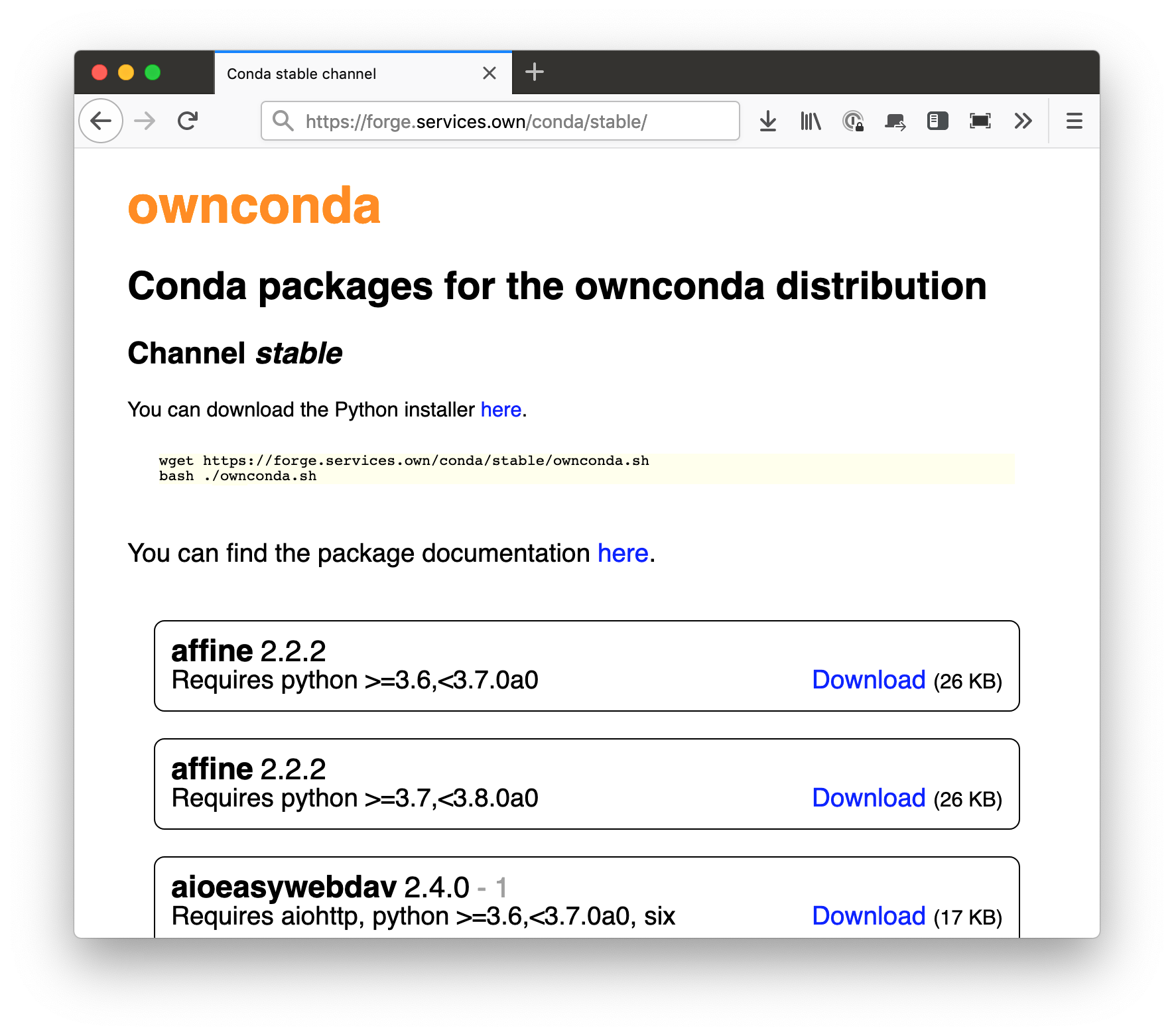
repodata.json.The upload service (for packages created in GitLab pipelines) resides under
https://forge.services.own/upload/<channel>. It is a simple web
application that stores the uploaded file in channel/linux-64 and runs
conda index. For packages uploaded to the stable channel, it
also creates a hard link in a special archive channel.
Every week, we prune our channels with ownconda prune-index. In case that we accidentally prune too aggressively, we have the option to restore packages from the archive.
We also host our own Read the Docs like service. GitLab pipelines can
upload Sphinx documentation to https://forge.services.own/docs via
ownconda make-docs.
Python distribution
With Constructor, you can easily create your own self-extractable Python distribution. These distributions are similar to miniconda, but you can customize them to your needs.
A constructor file is a simple YAML file with some meta data (e.g., the distribution name and version) and the list of packages that should be included. You can also specify a post-install script.
The command constructor <distdir>/construct.yaml will then download all
packages and put them into a self extracting Bash script. We upload the
installer scripts onto our Conda index, too.
Instead of managing multiple construct.yaml files manually, we create
them dynamically in a GitLab pipeline which makes
building multiple similar distributions (e.g., for different Python versions)
a bit easier.
Deployment
We are currently on the road from copy-stuff-with-fabric-to-vms to docker-kubernetes-yay-land. I am not going to go too much into detail here—this topic is not directly related to packaging and worth its own article.
Most of our deployments are now Ansible based. Projects contain an
ansible directory with the required playbooks and other files. Shared
roles are managed in a separate ownsible project. The ansible deployments
are usually part of the GitLab CI/CD pipeline. Some are run automatically,
some need to be triggered manually.
Some newer projects are already using Docker based deployments. Docker images are built as part of the pipeline and uploaded into our Docker registry from which they are then pulled for deployments.
Dependency management
It is very helpful if you can build a dependency graph of all your packages.
Not only can it be used to build all packages in the correct order (as we will shortly see), but visualizing your dependencies may also help you to improve your architecture, detect circular dependencies or unused packages.
The command ownconda dep-graph builds such a dependency graph from the packages that you pass to it. It can either output a sorted list of packages or a DOT graph. Since the resulting graph can become quite large, there are several ways to filter packages. For example, you can only show a package’s dependencies or why the package is needed.
The following figure shows the dependency graph for our python recipe. It
was created with the command ownconda dep-graph external-recipes/
--implicit --requirements python --out=dot > deps_python.dot:

These graphs can become quite unclear relatively fast, though. This is the full dependency graph for the ownconda tools:

I do not want to know how this would have looked if these were all JavaScript packages …
Making it work
Now that you know the theory of how everything should work, we can start to bootstrap our packaging infrastructure.
Some of the required steps are a bit laborious and you may need the assistance of your IT department in order to set up the domains and GitLab. Other steps can be automated and should be relatively painless, though:
Set up GitLab and a Conda repo server
- Install GitLab. I’ll assume that it will be available under
https://git.services.own. Setup the forge server. I’ll assume that it will be available under
https://forge.services.own:- In your www root, create a
condafolder which will contain the channels and their packages. - Create the upload service that copies files sent to
/upload/channelintowww-root/conda/channel/linux-64and callsconda index. - Setup a Docker registry on the server.
- In your www root, create a
Bootstrap Python, Pip and Conda
Clone all repositories that you need for the bootstrapping process:
$ mkdir -p ~/Projects/ownconda $ cd ~/Projects/ownconda $ for r in external-recipes ownconda-tools ownconda-dist; do \ > git clone git@gitlab.com:ownconda/$r.git \ > done
Build all packages needed to create your Conda distribution. The ownconda tools provide a script that uses a Docker container to build all packages and upload them into the stable channel:
$ ownconda-tools/contrib/bootstrap.shCreate the initial Conda distributions and upload them:
$ cd ownconda-dist $ python gen_installer.py .. 3.7 $ python gen_installer.py .. 3.7 dev $ cd - $ curl -F "file=@ownconda-3.7.sh" https://forge.services.own/upload/stable $ curl -F "file=@ownconda-3.7-dev.sh" https://forge.services.own/upload/stable $ $ # Create symlinks for more convenience: $ ssh forge.services.own # cd www-root/conda/stable # ln -s linux-64/ownconda-3.7.sh # ln -s linux-64/ownconda-3.7.sh ownconda.sh # ln -s linux-64/ownconda-3.7-dev.sh # ln -s linux-64/ownconda-3.7-dev.sh ownconda-dev.sh
You can now download the installers from
https://forge.services.own/conda/stable/ownconda[-dev][-3.7].shSetup your local ownconda environment. You can use the installer that you just built (or (re)download it from the forge if you want to test it):
$ bash ownconda-3.7.sh $ # or: $ cd ~/Downloads $ wget https://forge.services.own/conda/stable/ownconda-dev.sh $ bash ownconda-dev.sh $ $ source ~/.bashrc # or open a new terminal $ conda info $ ownconda --help
Build the docker images
- Create a GitLab pipeline for the centos7-ownconda-runtime project. This will generate your runtime Docker image.
- When the runtime image is available, create a GitLab pipeline for the centos7-ownconda-develop project. This will generate your development Docker image used in your projects’ pipelines.
Build all packages
- Create a GitLab pipeline for the external-recipes project to build and upload the remaining 3rd party packages.
You can now build the packages for your internal projects. You must create the pipelines in dependency order so that the requirements for each project are built first. The ownconda tools help you with that:
$ mkdir gl-projects $ cd gl-projects $ ownconda gitlab update $ ownconda dep-graph --no-third-party --out=project . > project.txt $ for p in $(cat projects.txt); do \ > ownconda gitlab -p $p run-py ../ownconda-tools/contrib/gl_run_pipeline.py \ > done
If a pipeline fails and the script aborts, just remove the successful projects from the
projects.txtand re-run theforloop.
Congratulations, you are done! You have built all internal and external packages, you have created your own Conda distribution and you have all Docker images that you need for running and building your packages.
Outlook / Future work and unsolved problems
Managing your organization’s packaging infrastructure like this is a whole lot of work but it rewards you with a lot of independence, control and flexibility.
We have been continuously improving our process during the last years and still have a lot of ideas on our roadmap.
While, for example, GitLab has a very good authentication and authorization system, our Conda repository lacks all of this (apart from IP restrictions for uploading and downloading packages). We do not want users (or automated scripts) to enter credentials when they install or update packages, but we are not aware of a (working) password-less alternative. Combining Conda with Kerberos might work in theory, but in practice this is not yet possible. Currently, we are experimenting with HTTPS client certificates. This might work well enough but it also doesn’t seem to be the Holy Grail of Conda Authorization.
Another big issue is creating more reproducible builds and easier rollback mechanisms in case an update ships broken code. Currently, we are pinning the requirements’ versions during a pipelines test stage. We are also working towards dockerized Blue Green Deployments and are exploring tools for container orchestration (like Kubernetes). On the other hand, we are still delivering GUI applications to client workstations via Bash scripts … (this works quite well, though, and provides us with a good amount of control and flexibility).
We are also still having an eye on Pip. Conda has the biggest benefits when deploying packages to VMs and client workstations. The more we use docker, the smaller the benefit might become, and we might eventually switch back to Pip.
But for now, Conda serves us very well.